AI Challenger English Chinese Machine Translation
Competitions ·Ai Challenger a new Chinese platform for ai challenges, their first contest was related to machine translation system and I wanted to try my techniques in NMT systems on a system that I have no clue about its target Chinese language.
In that contest I participated as Marb and got 25.50 bleu score on their evaluation .
Introduction
The challenge was to translate English transcripts to Chinese challenges without having knowledge of the target language.
Technical Aspects
Preprocessing
Each input sentence from Chinese and English corpus was tokenized using Stanford tokenizer, these sentences are then used to learn BPE codes with 60k operations (number of subwords operations which will reflect on the required output vocab size) (Subwords technique to get a smaller vocab size in NMT).
After applying the bpe codes on the input corpus, a vocab file was then created for the NMT model for training.
Model
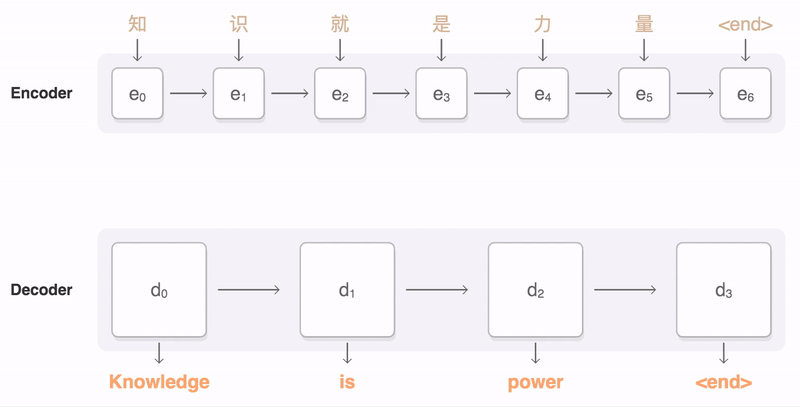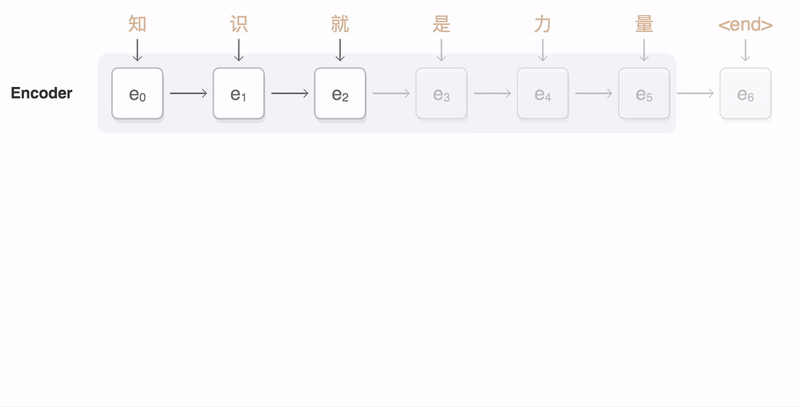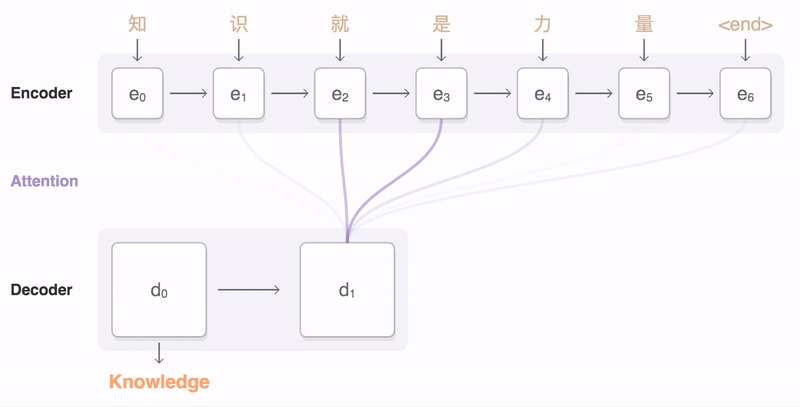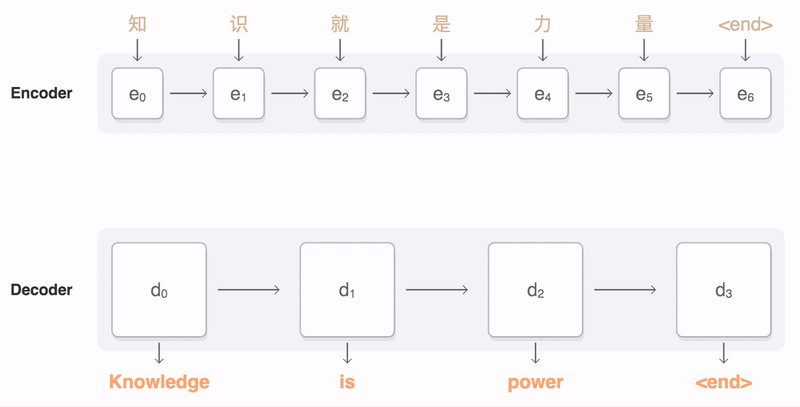
An attentional encoder decoder NMT model was trained on the data, its hyper parameters was tuned based on a selected subset of the data then I applied a full training on shuffled version of the input corpus.
Observation
This baseline model scored 25.5 on their test set which is good for a NMT model, but NMT training is expensive it took 3 days of training on this large corpus set.
BPE subword performance in Chinese language was not good, Chinese language treats spaces as a normal character like a,b in English and BPE separate tokens using spaces causing a small loss of information.
A better system could be made using word pieces in the case of Chinese instead of BPE as it treats a space as a character which is convenient with the Chinese system.
A statistical phrasal system trained with MOSES on the full corpus acting as a fallback to the main NMT system would improve the model results
Conclusion
This contest was a good opportunity to gain a good knowledge in NMT systems and to read about several techniques to get a better model.
Reference
- Created a fork from google seq2seq for this contest and fixed some bugs related to unk mapping during beam search, added GNMT model and added support for multiple GPUs. check the code at https://github.com/mostafaelaraby/seq2seq