Synthetic Spoken Data for Neural Machine Translation
Publications ·During my work at Microsoft Research Lab in Cairo , my first task was to make a Levantine Arabic dialect to English NMT system, but the parallel data available for dialectical Levantine was not enough to train a decent model for Skype translator.
Hany Hassan , me and Ahmed Tawfik had an idea to generate artificial dialectical parallel data based on available monolingual data (Hassan Awadalla et al., 2017).
Introduction
We introduce a way to generate synthetic data for training Neural Machine Translation System for low resource systems. Our approach is language independent and can be used to generate data for any variant.
Data Generation
Our Data Generation approach is based on distributional representation of words Since the sub-clusters in the embedding space contain similar word We exploit those characteristics to design our data generator
Required Data
We need parallel data between source standard input language (in the case of Levantine to English this was standard Arabic) and intermediate language (English language), seed parallel lexicons between source language and intermediate language, small seed parallel data between the intermediate language (English) and our low resource target language (Levantine).
These data along with the monolingual data for the 3 languages can be used to generate more parallel data between low resource language and the target language for NMT system.
Data preparation
We used Named Entity Recognition to avoid changing entities during the substitution of source language to the intermediate language.
Word2vec model was trained for each language based on its monolingual available corpora.
We directly use continuous representations learned from monolingual corpora such as Continuous Bag Of-Words (CBOW) representation.
In such continuous representation spaces, the relative positions between words are preserved across languages.
Approximated k-NN query technique is used to search for similar words near query word. A good approximation sacrifices the query accuracy a little bit, but speeds up the query by orders of magnitude
Three-way Semantic Projection
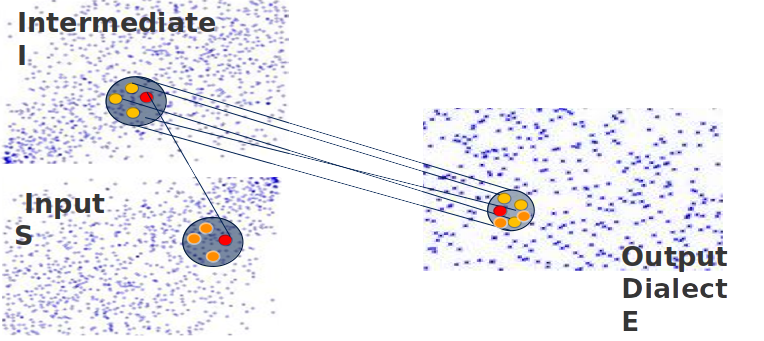
- Input word from Source language is mapped to Intermediate language I using input lexicons, these lexicons are extracted using a simple phrasal system on the input parallel corpus S and I
- We query the selected word in the I language for near N words having parallel mapping to target E language
- We use Local projection to get matrix W used to get the embedding vector of target E word from input word of intermediate Language I
Results
Levantine to English model
| Model | S2S_Test bleu |
|---|---|
| MSA Large System: includes all Levantine parallel data | 25.03 |
| MSA Large System + Adaptation using Levantine Data | 27.37 |
| MSA Large System + Lev GenCorpus | 27.91 |
| Oracle (Human translation to MSA+ MSA Large System) | 28.2 |
Egyptian to English model
| Model | CallHome_Test bleu |
|---|---|
| MSA Large System: includes subset of Egyptian parallel data | 15.7 |
| Egyptian Baseline: Trained with 210K parallel Egyptian data | 19.3 |
| Egyptian: Trained with 210K parallel data + EG GenCorpus | 19.7 |
Use Case
This data generation technique was successfully applied to generate more data to train Levantine to English conversational system for skype translate and was successfully made live at Jun 27 2018, check Microsoft blog for more info about the system Microsoft’s post and the approach used to train the model.
References
- Hassan Awadalla, H., Elaraby, M., & Tawfik, A. Y. (2017, December). Synthetic Data for Neural Machine Translation of Spoken-Dialects. IWSLT 2017. https://www.microsoft.com/en-us/research/publication/synthetic-data-neural-machine-translation-spoken-dialects/